Technical Concepts
This guide introduces the technical concepts Beamstack was built upon.
Abstraction Layers
Beamstack functions as a low-code abstraction layer designed to streamline the deployment of machine learning (ML) pipeline components. By providing a high-level interface that simplifies complex operations, Beamstack eliminates the need for direct modifications to underlying software development kits (SDKs) and APIs. This abstraction not only reduces the cognitive load associated with setting up ML workflows but also enhances accessibility for users across various expertise levels, from novices to advanced practitioners.
This entails:
Abstracted Configuration Management
- Beamstack abstracts the complexity of SDK and framework configurations. By utilizing a simplified command structure, Beamstack enables users to set up and modify ML pipelines without requiring in-depth knowledge of SDK-specific settings or detailed configuration files.
Streamlined CLI Interface
- Beamstack offers a robust CLI that facilitates the management of ML pipelines through intuitive command syntax. Users can execute various operations such as initializing projects, creating flink/spark clusters, deploying pipelines, and visualizing states of jobs with straightforward command-line inputs.
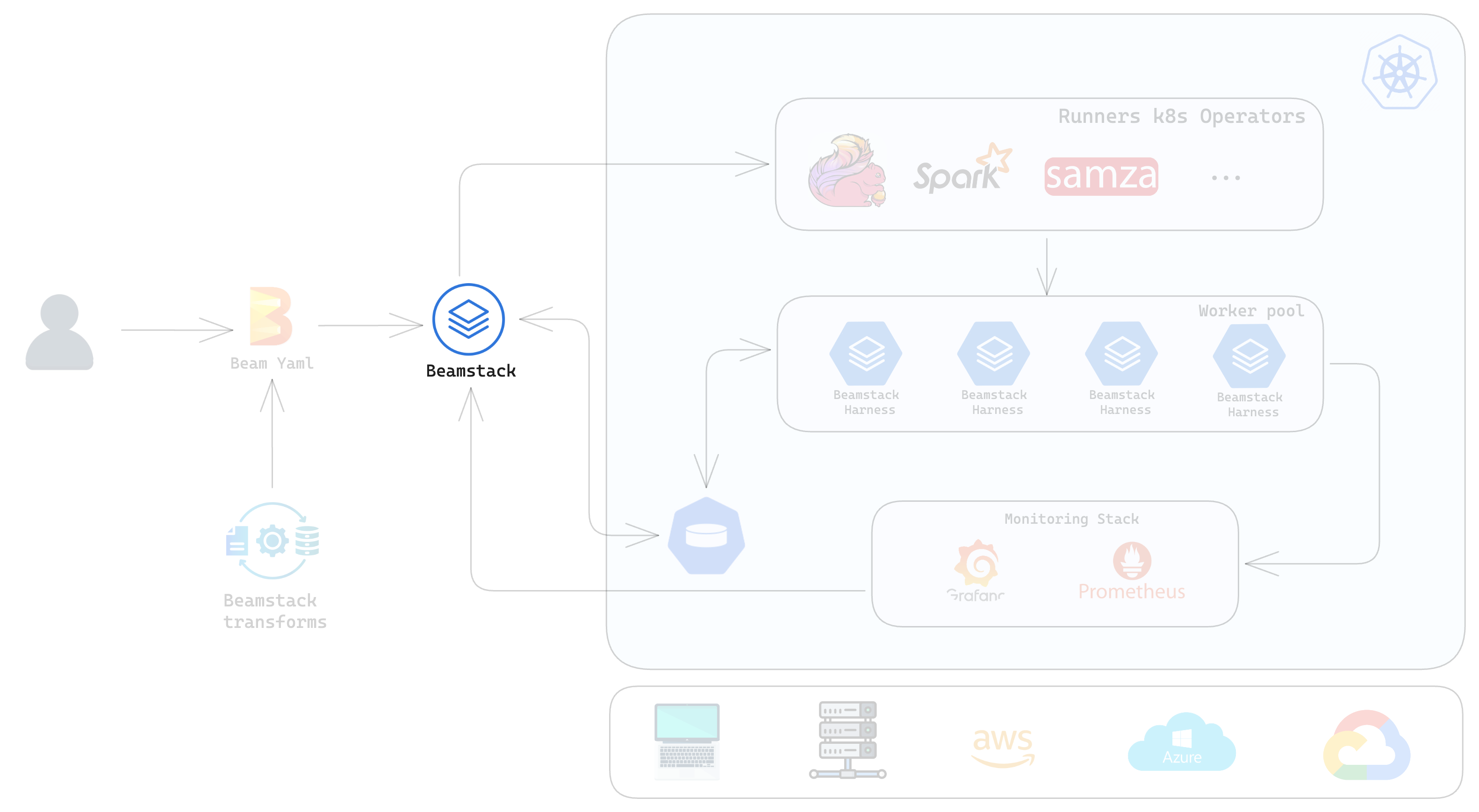
Monitoring and Visualization
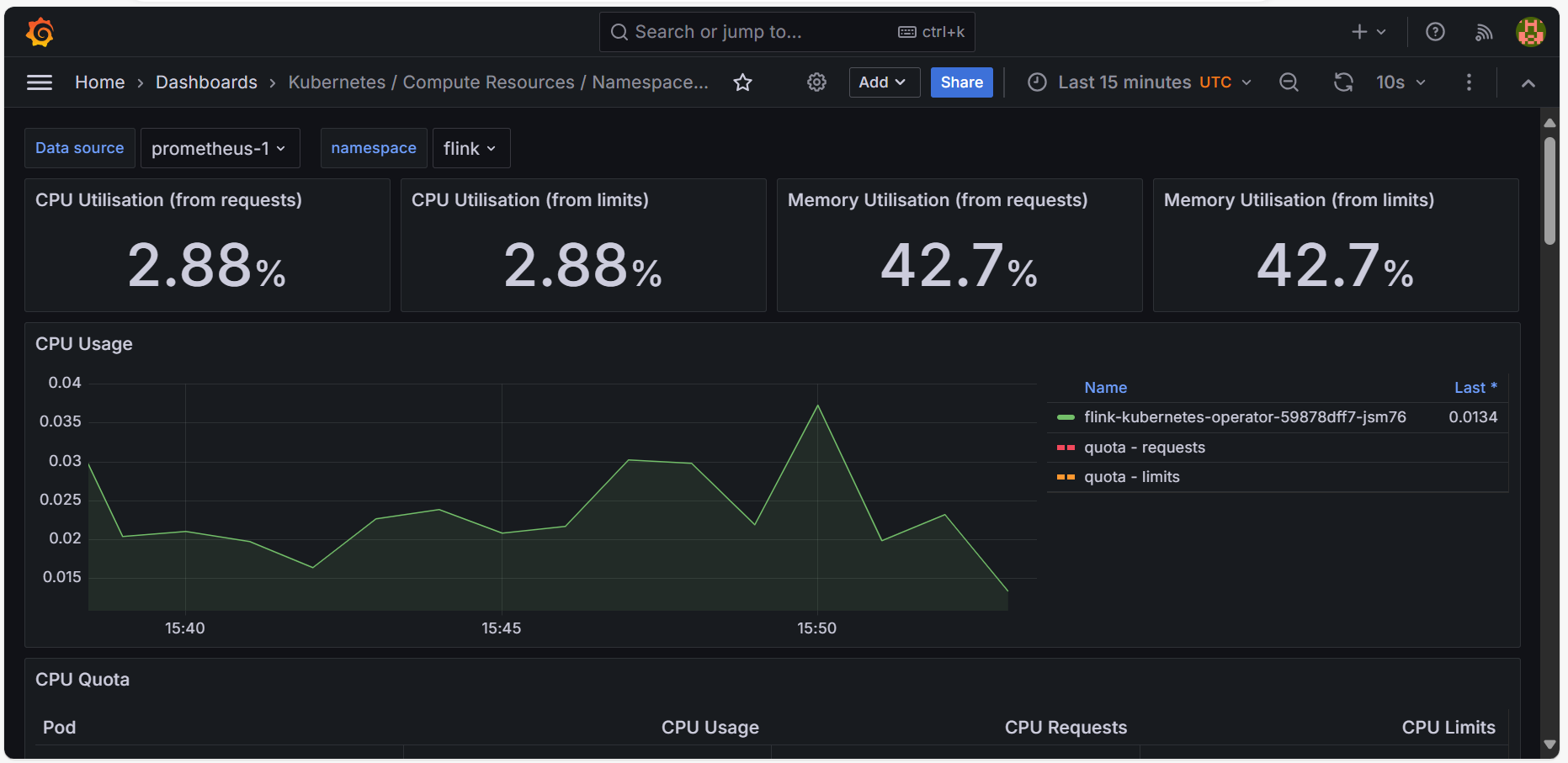
Beamstack includes an integrated monitoring stack featuring Grafana and Prometheus, designed to provide comprehensive visibility into the state of containers and resources within ML pipelines. This monitoring stack enables users to track performance, troubleshoot issues, and optimize resource utilization effectively.
This entails:
Prometheus Integration
- Real-Time Metrics Collection: Prometheus is employed for real-time collection of metrics from various components within the ML pipeline environment. It scrapes data from containers, services, and infrastructure to provide detailed insights into resource usage, performance, and operational status.
- Efficient Data Storage: Prometheus uses a time-series database to store metric data, ensuring efficient querying and retrieval of historical performance data. This facilitates trend analysis and long-term monitoring.
Grafana Visualization
- Custom Dashboards: Grafana integrates with Prometheus to offer customizable dashboards where users can visualize collected metrics through various types of charts, graphs, and tables. Users can create and configure dashboards to display key performance indicators (KPIs) and other critical metrics relevant to their ML pipelines.
- Interactive Data Exploration: Grafana provides interactive data exploration capabilities, allowing users to drill down into specific metrics, filter data, and generate ad-hoc queries. This interactive functionality aids in detailed analysis and troubleshooting.
Container and Resource Monitoring
- Container Metrics: The monitoring stack tracks various metrics related to container performance, including CPU usage, memory consumption, and network I/O. This helps users understand the resource demands of their ML pipelines and identify any bottlenecks or inefficiencies.
- Resource Utilization: Prometheus collects data on resource utilization across different parts of the infrastructure, such as node status, storage usage, and network traffic. Grafana dashboards present this information in an accessible and actionable format.
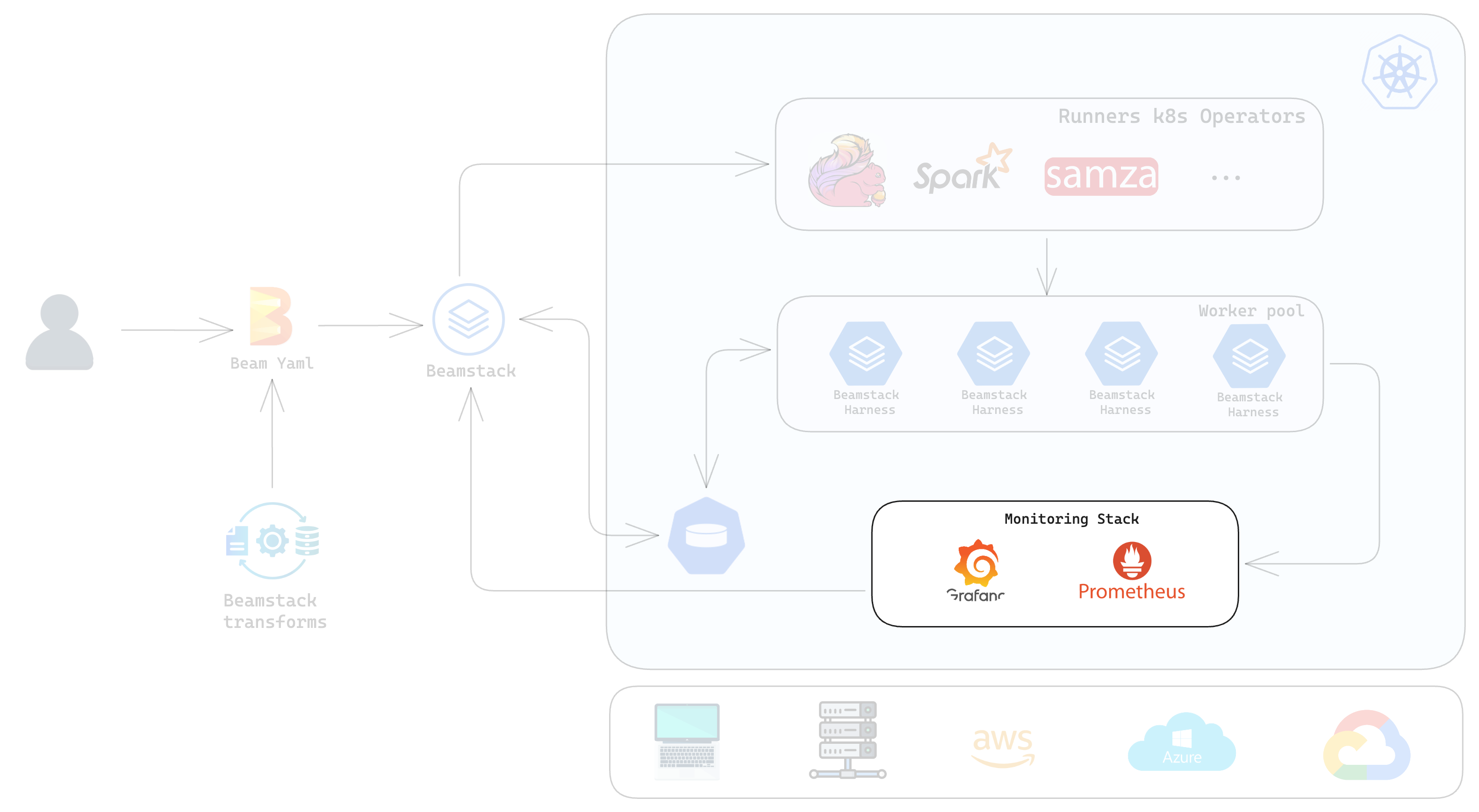
Intuitive Stack Configuration
- Setting up and configuring the monitoring stack is streamlined through Beamstack’s CLI and graphical interfaces. Users can easily define metric sources, configure dashboards, and manage alerting rules without extensive manual setup.
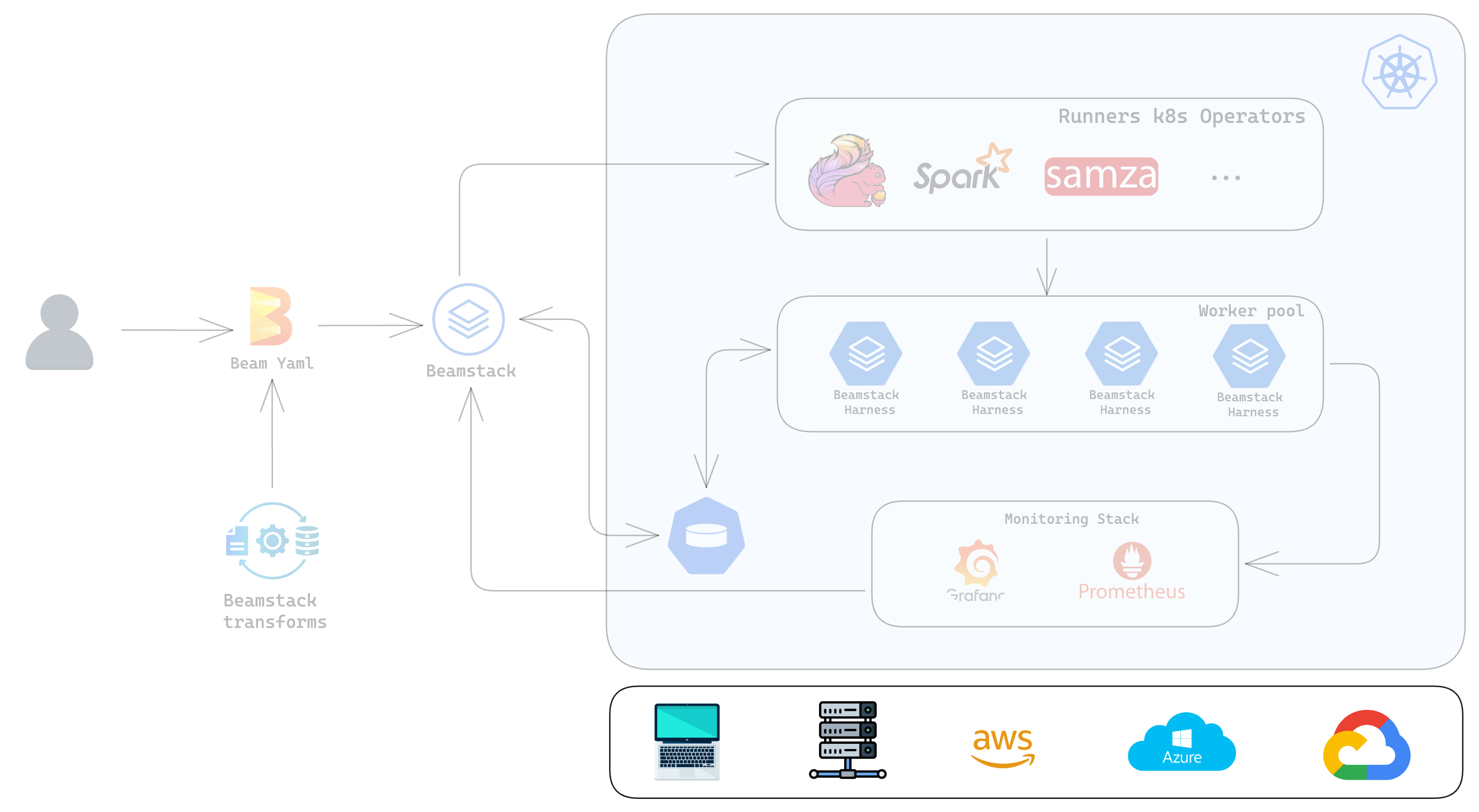
Infrastructure Agnostic Deployment
Beamstack ensures that users, regardless of their local setup, can seamlessly create and deploy their beam pipelines with minimal friction. By providing a consistent and versatile platform, Beamstack ensures that users, regardless of their local setup, can seamlessly create and deploy to local computers, baremetal boxes or any of the major cloud providers as long as they are running kubernetes.
This entails:
Environment-Agnostic Pipeline Development
- Consistent User Experience: Beamstack abstracts away the underlying differences between various development environments and operating systems, offering a unified interface for pipeline creation. Users can define, test, and deploy their pipelines without needing to adapt to specific environment constraints.
- Cross-Platform Compatibility: The tool is designed to work uniformly across multiple operating systems, including Windows, macOS, and various Linux distributions. This ensures that pipelines developed on one system can be deployed and executed on another without compatibility issues.
Flexible Development Environments
- IDE and CLI Integration: Beamstack supports integration with popular integrated development environments (IDEs) as well as command-line interfaces (CLI). Users can build and manage their pipelines using their preferred development tools, enhancing flexibility and productivity.
- Containerization Support: For enhanced consistency, Beamstack supports containerized environments (e.g., Docker). This allows users to encapsulate their development environment, ensuring that pipelines behave consistently regardless of the host system.
Unified Deployment Process
- Simplified Deployment: Beamstack streamlines the deployment process by providing a consistent set of commands and workflows for deploying ML pipelines. Whether deploying locally or to cloud-based environments, users follow the same straightforward procedures.
- Environment Configuration: The tool automatically handles environment-specific configurations and dependencies. Users define their pipeline components and configurations once, and Beamstack manages the adaptations required for different deployment targets.
Cross-Platform Pipeline Execution
- Platform Agnostic Execution: Beamstack ensures that pipelines execute consistently across various platforms. It abstracts platform-specific execution details, so users experience uniform performance and behavior regardless of the underlying system.
- Resource Management: The tool intelligently manages resources and dependencies according to the target environment, optimizing performance and ensuring that pipelines run efficiently across different operating systems.
User Experience Consistency
- Unified Interface: Beamstack provides a consistent user interface and experience, whether users are operating from different OS environments or using different development setups. This consistency reduces the learning curve and accelerates the development and deployment process.
- Documentation and Support: Comprehensive documentation and support resources are available to assist users across different environments. This includes platform-specific guidelines, troubleshooting tips, and best practices to ensure smooth operation regardless of the user's setup.
Scalability and Portability
Beamstack is designed to scale with the needs of diverse environments, from individual workstations to large-scale cloud infrastructures. This scalability ensures that users can deploy and manage ML pipelines effectively, regardless of the size or complexity of their infrastructure. Pipelines developed with Beamstack are portable across different environments, allowing users to easily move and deploy their workflows from development to production or from one system to another.
Feedback
Was this page helpful?
Glad to hear it!.
Sorry to hear that. Please tell us how we can improve.